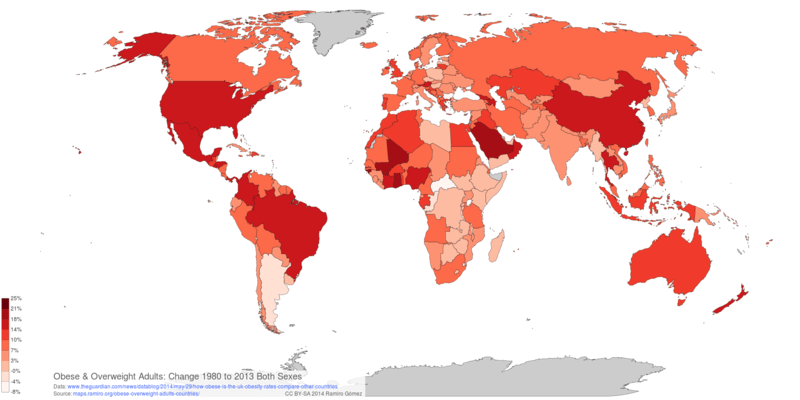
Obese and Overweight Adults¶
This notebook shows how to process data on obesity and overweight published by the Guardian to create Web based maps.
In [1]:
import io
import requests
import pandas as pd
from geonamescache.mappers import country
country_name_to_iso3 = country(from_key='name', to_key='iso3')
df = pd.read_excel('data/Overweight and Obesity data - IHME.xlsx', 'Obesity Overweight Adults', skiprows=1)
df.head()
Out[1]:
Create iso column from country names, then set country to index, so it can be easily omitted when saving.
In [2]:
df['iso3'] = df['country'].apply(country_name_to_iso3)
df.dropna(subset=['iso3'], inplace=True)
df.set_index('country', inplace=True)
Remove all Rank columns, as they are useless in the map display. Also remove repeating info from column names.
In [3]:
for col in df.columns:
if col.startswith('Rank'):
del df[col]
df.columns = df.columns.map(lambda x: x.replace(' ≥ 20', ''))
Convert float values back to percentages as integers.
In [4]:
def percentage(x):
if isinstance(x, float) and not np.isnan(x):
x = int(x * 100)
return x
df.applymap(percentage)
df.sort('Prevalence 2013 Both Sexes', ascending=False).head(20)
Out[4]:
Save data as CSV, and output column list.
In [5]:
df.to_csv('../static/data/csv/obese-overweight-adults-countries.csv', encoding='utf-8', index=False)
', '.join(["'%s'" % col for col in df.columns if col != 'iso3'])
Out[5]:
Volcano Map Poster
Recommended Books

IPython Interactive Computing and Visualization Cookbook

Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython

Python Data Visualization Cookbook
Links to Amazon and Zazzle are associate links, for more info see the disclosure.

About this post
This post was written by Ramiro Gómez (@yaph) and published on August 08, 2014.
blog comments powered by Disqus